Special thanks to Abhi and Alex for feedback
Introduction
While the theory behind the Data Availability (DA) problem has been discussed for years, these are the years we’re seeing solutions become reality on the Ethereum network. And while there are some very good explainers about it (1, 2), I want to try to journey through the original problem and the ingenious solutions that were found and not delve so much on the details of it all.
You may have heard of the Dencun upgrade where EIP-4844 (Proto-Danksharding) was launched, creating blobs. In May 2025, the Pectra upgrade went live; looking ahead, PeerDAS (EIP-7594) is planned for the Fusaka upgrade. Ethereum is laying the foundations for a scalable blockchain and the Data Availability Problem (DAP) is at the centre of it.
My goal here is not to provide a specific post talking about how DAS is being implemented, but rather to discover how the problem first came to be, how it was formulated and what the solutions to it are. It's a more general description rather than a specific one.
The Rise of the Data Availability Problem
I want to take you back to 2018, when the DA problem was first formulated. The issue Ethereum was trying to solve back then was the security asymmetry between light nodes and full nodes. On the single L1 chain, there were two types of nodes:
- Full nodes, which download all proposed blocks and execute all transactions.
- Light nodes, which simply download block headers.
With that in mind, think about state correctness. For full nodes, it's simple: they re-execute every transaction, so they can verify the state transition is valid. Light nodes, however, only see the headers, so they can't know if an invalid transaction is hidden inside a block. The proposed solution was to have full nodes create and broadcast fraud proofs for incorrect state transitions. With a of honesty assumption, light nodes could be alerted to invalid blocks (you only need one honest full node to act).
But an issue remains! Here is the Data Availability Problem:
- A malicious block producer publishes a block header and propagates it but... the block producer withholds a portion of the block data.
Since a portion of the block is withheld, honest full nodes can't generate a fraud proof. Their only option is to raise an alarm, stating that part of the block is missing. But here comes the core issue: ambiguity.
Imagine a full node , raises an alarm: "I'm missing chunk 42!". The malicious producer can immediately broadcast chunk 42. Another full node, , might receive chunk 42 first, and then see 's alarm. From 's perspective, is the liar launching a DoS attack. There is no way for the network to reliably agree on who was malicious. This makes any reward or slashing system based on alarms impossible to implement.
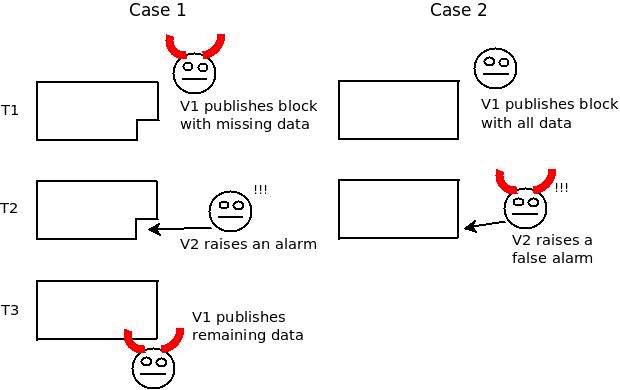 A representation of the DAP as originally defined by Vitalik Buterin (Source: post)
A representation of the DAP as originally defined by Vitalik Buterin (Source: post)
A potential solution: Data Availability Sampling
To solve this, one idea is to have light nodes download small, random parts of the block. If enough honest light nodes exist, and they each successfully download different sections, we can be statistically confident the whole block is available. However, a malicious producer could withhold just a few bytes, and most samplers would miss it, erroneously thinking the block is fine.
This leads to a more interesting idea: force the block producer to add redundancy using erasure coding. This process extends the block from original chunks to total chunks (where ). The key property is that you can reconstruct the original chunks from any of the chunks.
There are plenty of erasure codes, and one that is widely known is the Reed-Solomon (RS) code. In particular, one can build Reed-Solomon codes by starting from the coefficients of a polynomial (the message, of length ) and evaluating it at positions, treating that process as the encoding of the message, and obtaining a codeword of length . There is also a subtle way of doing something very similar by taking the message to be the first evaluations of the polynomial on a fixed set of points and then evaluating it on additional points. This is typically called the univariate low-degree extension or LDE of a polynomial, and importantly it is useful to encode our original data since it has the same properties as the RS code does, it allows us to reconstruct the original data from any of the points.
"A note on terminology. In the coding theory literature, is referred to as a message and the encoding is called the codeword corresponding to message . Many authors use the term Reed-Solomon encoding and low-degree extension encoding interchangeably. Often, the distinction does not matter, as the set of codewords is the same regardless, namely the set of all evaluation tables of polynomials of degree at most over . All that differs between the two is the correspondence between messages and codewords. i.e., whether the message is interpreted as the coefficients of a polynomial of degree , vs. as the evaluations of the polynomial over a canonical set of inputs such as ." Proofs, Arguments and Zero-Knowledge by Justin Thaler
If you are interested in understanding it more in-depth, I advise you to read Section 2 on Thaler's book. For now, this is enough to continue with our explanation.
Let's break down how we turn block data into a polynomial, we'll use for the number of original points and we are assuming a 2-fold extension (meaning , or , also known as the code's "rate"):
-
Chunk the Data: We take our block data and split it into chunks, let's call them
-
Interpret them as Points: We treat each chunk as the -value of a point on a 2D graph. We can say chunk is the point , chunk is , and so on, up to
-
Find the Polynomial: A fundamental mathematical principle states that there is one unique polynomial of degree less than that passes through these points. We can find this polynomial by using Lagrange Interpolation, let's call it .
-
Extend the Data: Now, we "extend" our data by simply evaluating this same polynomial at new -coordinates. We calculate . These new evaluations are our redundant chunks. Since the polynomial is uniquely defined by points, having more of them allows us to use any out of the now evaluations to obtain the polynomial back, and hence the original chunks.
Now that we have the extended block and light nodes can sample it. Let's go through some cases:
1. The block proposer extended the block correctly
The producer correctly applied the erasure coding. Now, if they want to withhold even a small piece of data, since there are enough chunks to reconstruct the whole block (recall that with any chunks we can reconstruct chunks) then there is no point in them doing so! To pull it off, they must withhold (assuming the same 2-fold extension that we discussed before) more than half of the data.
If a single light client samples just 10 random chunks, the probability of them missing the withheld data is , which is less than 0.1%. With hundreds of clients sampling, it becomes a statistical certainty that the fraud will be detected.
2. The block proposer did not extend the block correctly
Here lies the problem. What if the producer creates the extended data with garbage values that don't follow the polynomial? Then everything we discussed before simply does not hold anymore!
Original proposals defined specialised fraud proofs to show that the extended block was incorrectly generated. Though some research was done for such a scheme, fraud proofs were still not good enough in terms of size and overall complexity. Therefore there seemed to be no efficient way to solve the problem. Luckily, there is a clever solution.
The fall of the Data Availability Problem: PCS
A Polynomial Commitment Scheme (PCS) is a cryptographic tool that allows someone to create a short, cryptographic commitment for a polynomial with two key properties:
- Binding: The commitment is uniquely tied to one specific polynomial.
- Evaluation Proofs: The prover can evaluate the polynomial at any point such that and produce a proof that anyone can verify using just the commitment, the point , and the claimed value .
Thus, the solution is to force the block producer to commit to their polynomial beforehand and then ensure that each sample we take is from that specific polynomial! The specific PCS used by Ethereum is called KZG (Kate-Zaverucha-Goldberg). In everyday terms: a PCS is like sealing your data (encoded as a polynomial) in a tamper-evident envelope that also lets you prove what the value is at any input without opening the whole thing.
You may already be familiar with a widely popular commitment scheme used in blockchains: Merkle Trees! They allow one to generate a commitment (a Merkle Root) and provide the value at any point with an opening proof (the leaf value along with a Merkle Proof). The key difference with respect to a PCS is that the latter commits to a polynomial via its evaluations and not just to any set of data. Since blobs effectively are polynomials, this is a perfect fit!
An important thing to note here is that KZG requires something known as a trusted setup. Said setup is required for the protocol to work. More importantly it also defines the degree bound that any polynomial used with the scheme must satisfy (meaning that the scheme will only allow you to commit to any polynomial up to the maximum degree ). In Ethereum, blobs are interpreted as degree < 4096 polynomials and therefore their trusted setup only allows to commit to polynomials of said degree.
"We can’t just have a larger setup, because we want to be able to have a hard limit on the degree of polynomials that can be validly committed to, and this limit is equal to the blob size." EIP 4844. Ethereum
This scheme elegantly solves our problem by making bad encodings impossible to prove. Let's look at the two ways a malicious producer could try to cheat:
Attack 1: Commit to the correct polynomial, but provide fake evaluation proofs.
The producer generates the correct polynomial from the original data and publishes the commitment . Now, a sampler requests the evaluation at point , which is in the producer's secretly corrupted part of the extension. The producer can't just send back a fake value. They must provide the value and an evaluation proof that links the value, the point , and the original commitment . Because the fake value doesn't lie on the committed polynomial , the PCS verification done by the light client using the evaluation proof fails and fraud is detected.
Attack 2: Create a malicious polynomial that matches the original data but diverges on the extension.
The producer tries to create a fraudulent polynomial that matches the real polynomial on the first points (the original data), but gives different results for the extended data. They then publish a commitment to this fake polynomial.
Importantly, recall that there is a unique polynomial of degree less than that passes through points. Since both and must have degree less than (because of the degree bound we discussed earlier) and they must match on the first points (they represent the same original data), they must be the exact same polynomial. It is mathematically impossible for to be different from . Since two distinct polynomials of degree can agree on at most points, it means that agreement on points forces equality.
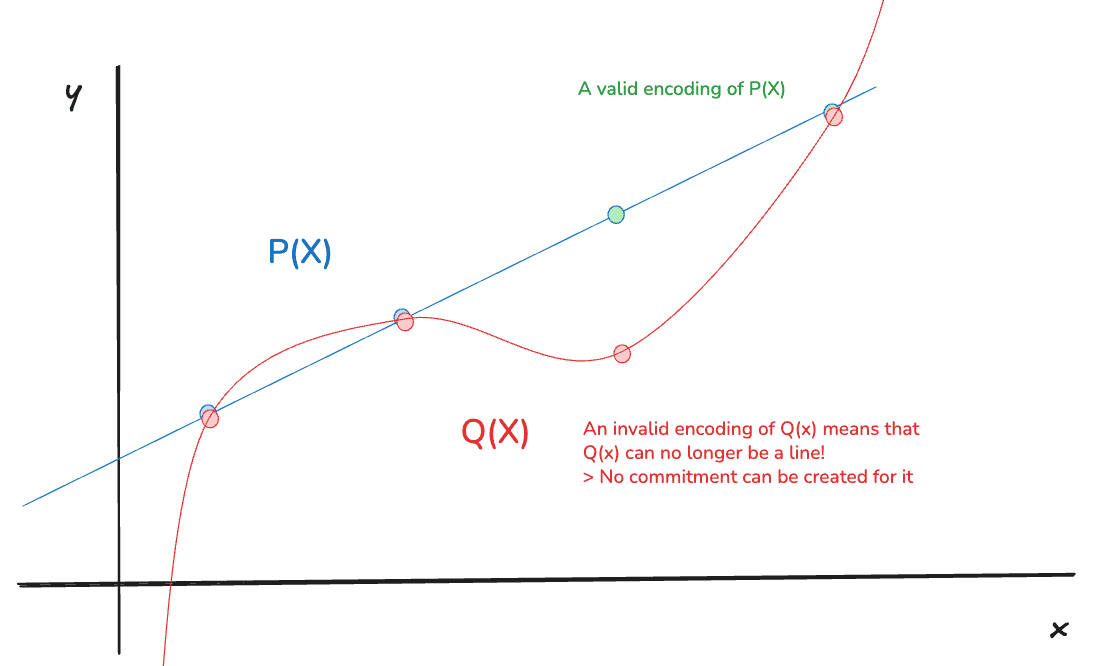 A representation of how and must be the same polynomial or a higher degree polynomial is required instead. Polynomials are not up to scale
A representation of how and must be the same polynomial or a higher degree polynomial is required instead. Polynomials are not up to scale
In other words, if you imagine a polynomial that is defined by two points, that would be a line. An attacker would use the same starting line (the original data), but try to encode it maliciously by giving other points that are not part of that line. Now, that means that we have two polynomials and that pass through two points, thus they must have degree or (only possibilities that are strictly less than ), and if they do they must be the same line already determined by (because said polynomial must be unique). Hence, if was wrongly encoded (by evaluating on a point that falls outside of the line), it would immediately be at least a degree polynomial (a quadratic function), and we cannot generate a valid commitment for it!
This is the magic of the PCS: It makes the data self-authenticating. A commitment to the first points is implicitly a commitment to all points of the correct extension. There is no longer a need for fraud proofs for bad encodings because a "bad encoding" with a valid commitment simply cannot be constructed.
So what about light nodes?
The original Data Availability Problem was indeed about securing L1 light clients. However, in the years it took to research and develop a full DAS solution, two things happened:
- A more immediate solution for L1 light clients was developed: Sync Committees. This provides a weaker security guarantee (trusting 2/3 of a 512-member committee) but was much faster to implement.
- Rollups emerged as the primary scaling strategy for Ethereum, and they had a massive need for cheap, secure data availability.
Therefore, the powerful DAS + PCS machinery, originally theorised for light nodes, was repurposed to become primordial for rollup scaling. Danksharding is part of the solution to the Data Availability Problem for rollups.
Conclusion
From a seemingly simple problem of securing light clients, we've journeyed through data sampling, erasure codes and commitment schemes. These lead to learning about powerful ideas such as the redundancy of erasure codes and the mathematics behind polynomials, bringing us closer to solving the DAP!
We are currently witnessing the rollout towards PeerDAS with the full vision of Danksharding as its culmination. These are the ideas that will allow Ethereum to scale while retaining its core security guarantees.